The Inference Router: A Critical Component in the LLM Ecosystem
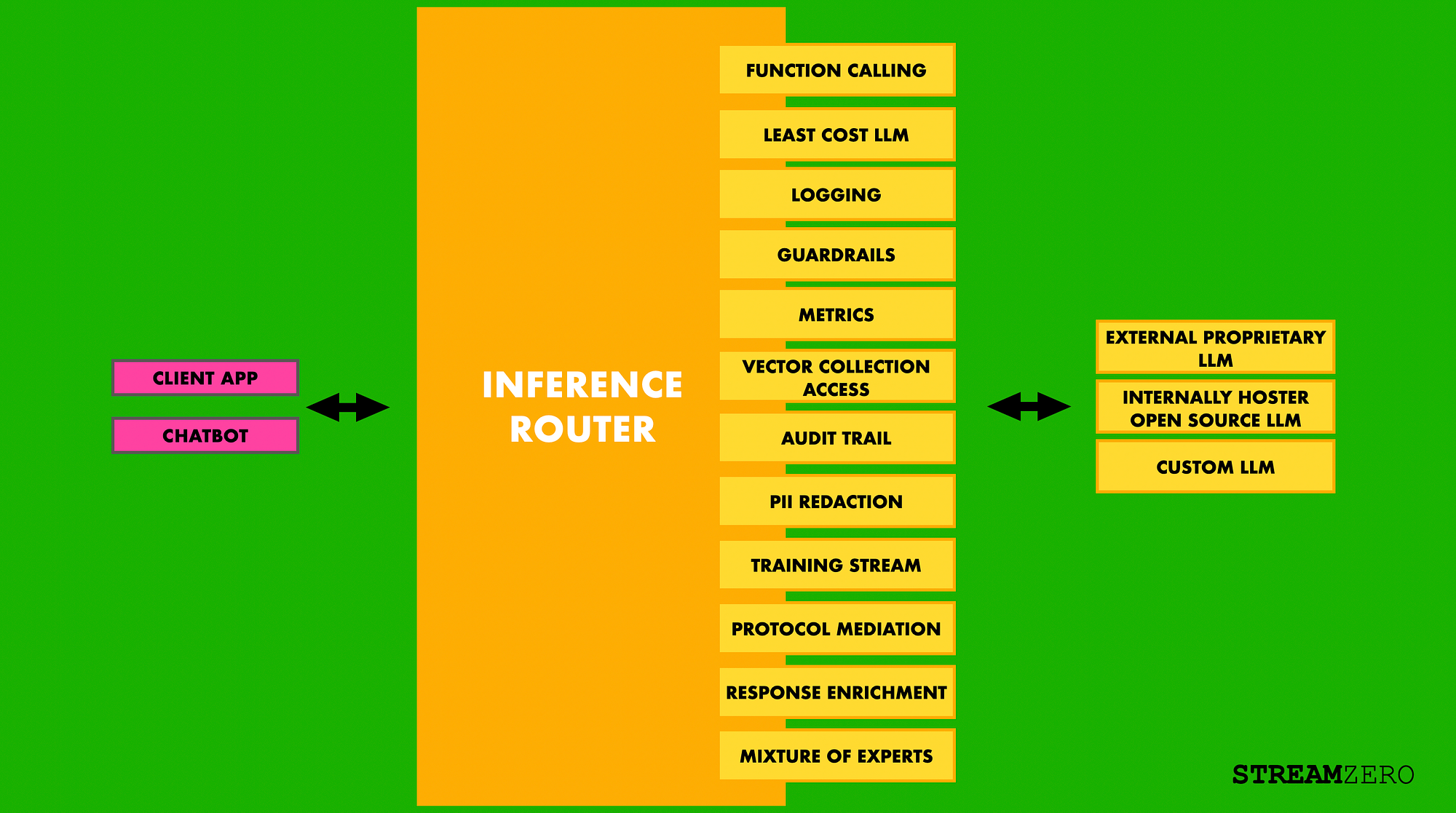
As large language models (LLMs) continue to permeate software architectures, a new set of challenges has emerged around optimising their performance, cost, and management at scale. In particular, if you’re working in non-trivial, high-volume environments as we do at StreamZero , efficiently managing the routing of LLM requests is not just an optimisation — it’s a necessity.
At the heart of these optimisations is the inference router, a rather simple yet powerful concept that is becoming increasingly indispensable in the LLM ecosystem. Whether it’s routing traffic to the least expensive model, capturing analytics, or adding governance controls, the inference router serves as a critical middleware layer that streamlines and optimises how LLMs are used in production environments.
So a definition would be : An inference router is a middleware component in machine learning and large language model (LLM) ecosystems that dynamically manages and optimizes the flow of inference requests to different models or services. Its primary role is to intelligently route incoming requests to the appropriate models based on factors such as task complexity, cost, latency, or availability of resources. The router can act as a cost-efficiency tool by directing simpler queries to cheaper models while reserving more complex tasks for advanced, expensive models. Beyond simple routing, it often incorporates functions like monitoring, guardrails, rate limiting, logging, and resiliency measures, ensuring that model interactions are not only optimized for performance and cost but also governed by predefined rules and safeguards. In essence, the inference router serves as the brains behind managing AI workloads in scalable systems, allowing flexible orchestration of model deployments in real-time.
In this article, we’ll dive into why inference routers are becoming so essential, the benefits they provide, and how we can build a basic yet functional implementation using FastAPI.
Why an Inference Router is Necessary
1. Cost Efficiency
With LLMs getting more powerful but also progressively expensive, cost optimisation is crucial for any organisation using these models at scale. An inference router allows you to intelligently route requests to cheaper models when appropriate while escalating more complex requests to premium models only when necessary. For instance, a straightforward task might be handled by a smaller, less powerful model, while a more nuanced query could be routed to a more specialized, high-end model.
This selective routing not only helps you optimise API costs but also allows you to balance performance with budget management, especially in environments where frequent, high-volume LLM transactions occur.
OpenRouter is a great example of an inference router which is focused on cost optimisation.
2. Capturing Metrics & Observability
Inference routers also serve as the central hub for gathering detailed metrics such as response times, success rates, and token usage. By centralising this data, organisations can analyze usage patterns, optimize their LLM deployment strategy, and track the performance of various models over time. This helps in identifying inefficiencies, enabling fine-tuned benchmarking, and making data-driven decisions to further improve both cost and performance.
Helicone is a good example for this category of inference routers.
3. Guardrails & Governance
One of the most critical aspects of an inference router is enabling guardrails for LLM interactions. This includes input validation, enforcing rate limits, adding retry logic for failed responses, and managing fallback mechanisms when a service goes down. These guardrails not only optimize performance but also provide an extra layer of security, ensuring that requests meet specific standards before being forwarded to the LLM for processing.
Guardrails is a good example within this category.
4. Scalability & Flexibility
Inference routers simplify scalable deployments by making it easier to swap out LLMs or add new ones without requiring sweeping changes across the entire application infrastructure. With a well-designed router, you can dynamically adjust how requests are routed based on need, reducing bottlenecks and improving system robustness.
Why Not Shift This Logic to the Client or AIFlow Platform?
The question may arise as to why we don’t simply place this inference routing logic on the client side or embed it directly into a model execution platform, such as our Streamzero AIFlow platform, which hosts over 1,600 models.
The answer is straightforward: the router is a highly capable and adaptable component, where functionality may evolve rapidly and dynamically. Offloading this complexity onto client-side applications (e.g., built-in Next.js or React) would bring about unnecessary complications and management overhead. Client-side routing logic can get increasingly difficult to maintain, impacting both scalability and flexibility.
Additionally, embedding routing into a centralised model execution platform like AIFlow could abstract the fine-grained control you need over routing and decision-making logic. By keeping the routing external, in a dedicated inference router, we maintain agility and governance without bloating client-side apps or hampering the flexibility of our middleware.
Sample Implementation with FastAPI
FastAPI was the default choice for implementing our inference router, and for good reason. First and foremost, we were already using FastAPI in other parts of our infrastructure, so adopting it minimised the integration effort.
Moreover, FastAPI offers minimal latency in processing both requests and responses, which is crucial in high-throughput, low-latency environments where rapid inference is required. Its native support for asynchronous execution allows us to handle multiple concurrent requests efficiently, further optimizing the router for performance and scalability.
What sets FastAPI apart is its ease of scaling across multiple replicas to handle increased load, and its compatibility with various deployment models, including distribution across platforms like Cloudflare Workers. All in all, FastAPI offers the perfect balance of performance, scalability, and simplicity, making it an ideal candidate for building an inference router.
Skeleton Implementation of an Inference Router with FastAPI
Let’s walk through a basic implementation of an inference router using FastAPI. While the actual router used in production is significantly more advanced, the skeleton implementation below covers the core concepts.
Step 1: Basic Setup with FastAPI
Start by installing FastAPI and Uvicorn (to serve the application):
pip install fastapi uvicorn aiohttpStep 2: Defining API Endpoints and Models
We’ll create a simple FastAPI application that routes a text query to different LLMs, depending on the text’s length (representing task complexity). In this toy example, shorter queries are routed to a ‘cheap’ LLM, and longer, more complex queries to a ‘powerful’ LLM.
from fastapi import FastAPI
from pydantic import BaseModel
import aiohttp
app = FastAPI()
class InferenceRequest(BaseModel):
text: str
async def query_model(endpoint: str, payload: dict):
async with aiohttp.ClientSession() as session:
async with session.post(endpoint, json=payload) as response:
return await response.json()
CHEAP_LLM_ENDPOINT = "http://cheap-model/api"
POWERFUL_LLM_ENDPOINT = "http://powerful-model/api"
@app.post("/route-inference/")
async def inference_router(req: InferenceRequest):
text = req.text
if len(text) < 50:
response = await query_model(CHEAP_LLM_ENDPOINT, {"text": text})
else:
response = await query_model(POWERFUL_LLM_ENDPOINT, {"text": text})
return {"response": response}This is a basic example of routing queries based on their complexity (in this case, text length). In production, you could include more sophisticated logic like evaluating request metadata or specific user preferences to decide which model to invoke.
Step 3: Advanced Routing & Guardrails
Our internal implementation handles complex routing logic, retries, and fallbacks. Additionally, it integrates with logging, monitoring, and billing systems such as Lago. Here’s an illustration of how advanced routing logic can look:
@app.post("/advanced-inference/")
async def advanced_inference_router(req: InferenceRequest):
text = req.text
try:
if len(text) < 100:
response = await query_model(CHEAP_LLM_ENDPOINT, {"text": text})
else:
response = await query_model(POWERFUL_LLM_ENDPOINT, {"text": text})
except Exception as e:
# Implement fallback mechanism
print(f"Error: {e}, routing to fallback model...")
response = {"response": "Fallback LLM response"}
return {"response": response}Step 4: Billing and Event Generation
While the code provided is a skeleton, our in-house implementation includes complex aspects, such as Lago billing event generation for tracking usage and costs associated with each inference request. This ensures that every interaction, whether routed to an internal model or an external API, is properly billed based on the resources consumed. By integrating Lago, we can precisely calculate costs, manage quotas, and produce financial reports accordingly.
Extending the Inference Router with FastAPI Middleware: Request and Response Processing
One of FastAPI’s most powerful features is its support for middleware — an architecture where you can define code that gets executed before and after each request. FastAPI middleware provides a flexible, streamlined way to extend functionality across all routes in your app for processes like authentication, logging, or data modification. In our context, we’ll explore how to extend the inference router by using middleware to enrich the request and response processing.
Specifically, middleware can help us achieve several goals:
-
Pre-process incoming requests: Validate or sanitize user inputs, check for rate limits, modify headers, or filter anomalies in the input data before handing the request to the router.
-
Post-process responses: Adjust response formats, capture performance metrics, add logging, or even generate events such as billing.
Let’s articulate this via an example where we:
-
Log incoming requests and outgoing responses.
-
Track request processing time (response latency) for performance monitoring.
-
Sanitize the input data before routing to an LLM.
-
Capture additional response metadata for billing purposes.
Step 1: Defining Middleware
To introduce middleware in FastAPI, it’s as simple as defining an asynchronous function that implements the required logic and then registering it in the FastAPI app as a middleware.
from fastapi import FastAPI, Request
from time import time
app = FastAPI()
@app.middleware("http")
async def log_requests(request: Request, call_next):
# Step 1: Log request data
start_time = time()
print(f"Request path: {request.url.path}")
print(f"Request method: {request.method}")
# Step 2: Pre-process the request (e.g., input sanitization)
sanitized_body = await sanitize_request(request)
# Step 3: Pass the request forward to handler, and get the response
response = await call_next(sanitized_body)
# Step 4: Post-process the response (e.g., attach latency, log)
process_time = time() - start_time
response.headers["X-Process-Time"] = str(process_time)
print(f"Processed request in {process_time:.2f} seconds")
return responseExplanation:
-
Log Request Path and Method: We immediately capture the request details (e.g., path and method) and print them for logging purposes.
-
Input Sanitization (Pre-processing): Before forwarding the request down the chain, we call a custom function
sanitize_request()to clean or validate the incoming data. -
Request-Response Chain: We use
call_next(sanitized_body)to pass the modified (sanitized) request to the next middleware or route handler. -
Capture Latency (Post-processing): Once the response is returned, we calculate how long the request took to process and attach it to the response headers.
-
Log Outgoing Response: We also log how long the request took after it’s processed.
Step 2: Custom Request Sanitisation
Let’s implement the request sanitisation function. This will ensure that every incoming request is pre-processed before being routed.
from fastapi import Request
from fastapi.responses import JSONResponse
async def sanitize_request(request: Request):
try:
# Simulate retrieving request body and performing basic sanitization
request_body = await request.json()
# Example: Convert all text inputs to lowercase (a simplistic example)
if "text" in request_body:
request_body["text"] = request_body["text"].lower()
# Return sanitized request
return request_body
except Exception:
return JSONResponse(status_code=400, content={"message": "Invalid request format or data"})Explanation:
-
We retrieve the raw JSON body of the request using
await request.json(). -
Pre-process the
textinput, sanitizing it by converting to lowercase. -
We also include a basic mechanism to handle bad or malformed requests by returning a
400 Bad Requestresponse if the input is invalid.
Step 3: Capturing Additional Metadata and Logging Responses
We can extend the logging mechanism by capturing additional information about the response like memory usage, request token utilization, or billing-related metadata.
Let’s modify the post-request logging to add these metrics and log them efficiently:
@app.middleware("http")
async def add_response_metrics(request: Request, call_next):
# Start recording the request processing time
start_time = time()
# Call the route's handler and await the response
response = await call_next(request)
# Measure time taken for request processing
process_time = time() - start_time
response.headers["X-Process-Time"] = str(process_time)
# Simulating additional metadata collection (e.g., for billing or analytics)
token_usage = 100 # In a real scenario, this will be dynamically generated
request_size = len(await request.body())
response_size = len(response.body)
# Insert custom headers or logs for billing purposes
response.headers["X-Token-Usage"] = str(token_usage)
response.headers["X-Request-Size"] = str(request_size)
response.headers["X-Response-Size"] = str(response_size)
print(f"Response metrics - Tokens: {token_usage}, Request Size: {request_size} bytes, Response Size: {response_size} bytes")
return responseExplanation:
-
Token Usage Simulation: We’ve added a sample
token_usagemetric. In a real-world scenario, you could calculate how many tokens the LLM consumed to process the request and return the response. -
Request & Response Size: We capture the sizes (in bytes) of both the incoming request and outgoing response to generate further insights useful for billing or data management.
-
Custom Headers: The middleware dynamically augments the response headers with these additional metadata points (
X-Token-Usage,X-Request-Size,X-Response-Size) so the client can also observe this information.
Step 4: Running the FastAPI Application with Middleware
Finally, let’s see how we can integrate the middleware into a functional FastAPI app where we route requests for LLM interaction:
from fastapi import FastAPI, Request
from pydantic import BaseModel
import aiohttp
app = FastAPI()
class InferenceRequest(BaseModel):
text: str
async def query_model(endpoint: str, payload: dict):
async with aiohttp.ClientSession() as session:
async with session.post(endpoint, json=payload) as response:
return await response.json()
CHEAP_LLM_ENDPOINT = "http://cheap-model/api"
POWERFUL_LLM_ENDPOINT = "http://powerful-model/api"
@app.post("/route-inference/")
async def inference_router(req: InferenceRequest):
text = req.text
# Routing decision made based on text length
if len(text) < 50:
response = await query_model(CHEAP_LLM_ENDPOINT, {"text": text})
else:
response = await query_model(POWERFUL_LLM_ENDPOINT, {"text": text})
return {"response": response}Explanation:
The app routes POST /route-inference/ requests based on the query length and leverages the middleware to ensure:
-
Request sanitation before the routing logic is processed.
-
Logging and capturing additional metadata for enhanced debugging, performance analysis, and billing.
Running the App:
Run the FastAPI app using uvicorn:
uvicorn app:app --reloadNow, when you send requests to /route-inference/, the middleware will:
-
Log the details of the request.
-
Sanitize incoming data (like converting text to lowercase).
-
Capture valuable performance and request/response size metrics.
-
Attach this data as custom headers in the response for potential consumers.
Conclusion
FastAPI middleware allows you to extend the capabilities of your inference router far beyond simple request routing. By using middleware:
-
You can pre-process and sanitize incoming requests to ensure they meet the necessary standards before routing.
-
You can track detailed metrics such as billing-related data, request/query size, token consumption, and overall performance.
-
You enable robust logging and observability, ensuring you gain insights into how the inference router is performing under various conditions.
This approach allows the router to become an adaptable, dynamic piece of middleware capable of handling complex real-world requirements, from performance tracking to billing integrations, all without bloating the core application logic.
As LLMs continue to power more applications, inference routers are becoming a core element of any scalable AI infrastructure. They ensure cost-efficient routing, capture metrics for continuous improvement, enforce guardrails for secure and reliable usage, and provide the agility needed to evolve rapidly in high-volume, dynamic environments.
FastAPI is an excellent framework for building such a router, offering speed, flexibility, and scalability. While the implementation details may grow as complexity increases — such as integrating with billing systems like Lago or handling intelligent fallback mechanisms — the skeleton code provided here illustrates the essentials of dynamically managing LLM requests.
If you’re planning on building or optimising a high-volume LLM architecture, consider implementing an inference router. Whether in a research project or a production environment, the router will ensure that you’re not only maximizing performance but also controlling costs effectively.
References: